This webinar will give an overview about RadCalc and its automated workflows. It will not only cover single RadCalc installations but also show how a multi-user or multi-institution structure is set up as and can be managed. In addition, participants will learn how RadCalc supports secondary dose check calculations from a home office or other remote location.
The presenter, Tamas Medovarszki, will cover the following:
Learn how to set up multiple institutions.
Find out about customizable templates, physics setup and automations.
Get to know different remote access possibilities.
Tamas Medovarszki, physicist, product specialist. Tamas joined LAP Laser in 2020. He has several years experience in radiation therapy, dosimetry and working with medical devices. With his clinical and industrial background his main goal is to support LAP and the customers in the application of the software-based QA procedures in radiation therapy.
Independent verification always has been, and likely always will be, the core value proposition for RadCalc QA secondary check software. For more than two decades, this suite of widely deployed quality assurance (QA) tools has provided medical physicists and dosimetrists with fully automated and independent dosimetric verification of their radiotherapy treatment planning systems (TPS). What’s more, ongoing product innovation saw the RadCalc value proposition advance significantly last year with the clinical roll-out of automated 3D dose-volume verification – a result of the successful integration of Monte Carlo and collapsed-cone convolution superposition algorithms into the platform.
“With 3D dose verification, we’re offering end-users a higher degree of certainty that the planning treatment volume is being validated, while assisting in the evaluation of plan quality by comparing dose to adjacent critical structures and organs at risk,” explains Craig Laughton, CTO and co-founder of the RadCalc software portfolio, part of LAP’s growing QA product line in radiotherapy. “That certainty translates into better targeting accuracy and dose distribution accuracy – and ultimately enhanced treatment outcomes – for the more than 2300 cancer centres that use RadCalc on a daily basis for patient QA.”
Craig Laughton: “With 3D dose verification, we’re offering end-users a higher degree of certainty that the planning treatment volume is being validated.” (Courtesy: LAP)
As part of that QA workflow, all the physicist has to do is export a treatment plan via their DICOM RT and RadCalc will automatically verify the plan using either a Monte Carlo or collapsed-cone algorithm, generating results in minutes. If the treatment plan doesn’t pass various preset criteria, RadCalc will prompt the user to investigate what’s going on using a suite of dose analysis tools.
“The user can slice-and-dice the plan just about any way they want by using our proven traditional workflows,” adds Laughton, “while RadCalc’s new dependable features evaluate the cause of any discrepancies and determine the course of action.”
A 3D take on patient QA
Among the early-adopters of RadCalc’s collapsed-cone convolution superposition algorithm are Joshua Robinson and colleagues at the James A Haley Veterans’ Hospital in Tampa, Florida. Robinson is one of four medical physicists within the clinic’s radiation oncology programme, overseeing a suite of three Varian treatment machines (including a new TrueBeam Edge system that’s currently being commissioned) and an Accuray CyberKnife treatment system, a robotic radiotherapy platform widely deployed in treating a range of disease indications using stereotactic radiosurgery (SRS) and stereotactic body radiotherapy (SBRT).
“Our clinic supports cancer treatments across a predominantly male cohort of military veterans – so we see a lot of prostate, lung and head-and-neck patients,” explains Robinson. When it comes to patient QA, the James A Haley Hospital is a long-time RadCalc customer, with the product a key enabling technology in the “second-check everything” default setting of the radiation oncology department. “We like RadCalc functionality a lot – as well as all the support that comes with it,” Robinson adds. “The software offers a powerful engine for second-check QA calculations, while the intuitive reporting integrates seamlessly into our clinical workflow.”
As a “lighthouse customer”, the Tampa clinic was among the first beta test sites chosen to evaluate RadCalc’s automated 3D dose-volume verification functionality – and specifically the software’s new collapsed-cone convolution superposition algorithm. The motivation, says Robinson, is to maintain confidence in the QA accuracy across harder-to-treat clinical indications – for example, small tumour targets surrounded by lung heterogeneities – as well providing independent QA checks across a range of advanced treatment modalities, including SRS, SBRT, intensity-modulated radiotherapy (IMRT), volumetric modulated-arc therapy (VMAT) and hypofractionation.
“We’re still evaluating the collapsed-cone algorithm as part of our daily clinical practice,” notes Robinson. “One thing is already evident though: 3D dose verification increases your likelihood of getting a better, more accurate picture of dose distribution inside the patient. You’re doing the calculation on the planning CT – just like the TPS is doing the calculation on the planning CT – so you’re no longer just relying on a single dose point for the QA comparison.”
The software offers a powerful engine for second-check QA calculations
Joshua Robinson
That’s especially important in more challenging treatment planning scenarios such as advanced head-and-neck cancers and late-stage prostate and rectal disease – indications that often require larger, heavily modulated treatment fields that are problematic in terms of conventional point-dose QA checks. Near term, Robinson sees the biggest clinical opportunity for 3D dose verification in the hospital’s lung SBRT patients, allowing treatment planners to accommodate the high dose per fraction while providing confidence in the steep dose gradients calculated by the TPS.
“Depending on the size of the tumour and its location in the lung,” he notes, “a more complex planning technique is needed by the dosimetrists in order to achieve the steep dose gradients that minimize dose to the adjacent chest wall, heart and normal blood vessels. The Gamma Analysis and 3D comparison functionality in RadCalc help us to maintain confidence in the treatment plan along with our patient QA checks on the treatment machine.”
The QA roadmap
Right now, the RadCalc team is putting the finishing touches to the software roadmap for 2021 and beyond, including the imminent release of 3D EPID-based functionality to underpin true measurement-based IMRT QA and in vivo verification. In short, RadCalc will import the necessary EPID data/image files, process them, and then send to the collapsed-cone dose engine to calculate the dose. “The 3D EPID solution alongside delivery log-file analysis will provide the most comprehensive patient QA solution on the market,” concludes Laughton.
More broadly, RadCalc’s incorporation into the LAP group (in January 2019) has opened up new growth opportunities within the latter’s evolving product portfolio for radiation therapy. LAP’s offering for radiotherapy customers currently comprises laser systems for patient positioning, a suite of QA software and phantoms, as well as specialist beam-shaping technologies.
Schematic of the microaneurysm-on-a-chip platform with eight microaneurysms of varying sizes (A). Bright-field image illustrating blood flow in the microchip (B). A zoomed-in view of two microaneurysm channels (C) and a fluorescence-stained image of the same two channels (D). (Courtesy: Shengze Cai)
Quantifying the characteristics of microcirculation is essential for understanding how different vascular diseases, such as the rupture of microaneurysms in the eye’s blood vessels, arise. Current imaging techniques, including retinal photography analysis or optical coherence tomography, cannot deliver real-time observation of many in vivo biological processes that occur in microcirculation.
One potential solution is to develop microfluidic devices and laboratory-on-a-chip platforms to understand the mechanics of blood flow and the mechanisms of human vascular diseases. However, current approaches involve either analysing images of fluid flow or enforcing the underlying physics of blood flow without visualization, which can compromise the accuracy of predictions, particularly in vessels with complex geometries.
An AI algorithm trained on 2D images of blood flow…
To improve upon the existing techniques, an international team of researchers – from Brown University, Massachusetts Institute of Technology and Nanyang Technological University – has developed an artificial intelligence velocimetry (AIV) framework that can determine 3D flow fields using 2D imaging data and physics-informed neural networks. The platform has the potential for integration with existing imaging technologies to automatically infer key haemodynamic metrics from in vivo and in vitro biomedical images. The results are summarized in Proceedings of the National Academy of Sciences.
The scientists designed a microaneurysm-on-a-chip (MAOAC) platform that simulates common manifestations of diabetic retinopathy, a leading cause of vision loss arising from blood-vessel damage in the retinas of diabetic patients. More specifically, the researchers developed a microfluidic device capable of moving small amounts of fluid in tiny channels carved into a microchip. This in vitro set-up yielded 2D video images of blood flow, which the researchers used, together with the AI-powered platform, to predict blood flow characteristics.
… successfully predicts the characteristics of blood circulation
The MAOAC system contains eight microchannels with cavities of varying size, with the aim of mimicking different types of microaneurysm. The researchers drew blood from a healthy donor and used a 20 µL sample to fill the system and generate a flow pattern. During the experiment, they recorded video images at 500 frames/s with 1 µm/pixel resolution and used these as training data for the AIV platform to produce velocity fields. Additionally, they also recorded fluorescence images to perform cell-tracking measurements for AIV validation.
AIV predictions showing the 3D computational domain (A) with 25 µm in the z-direction; velocity (B) and pressure fields (C) at three different cross-sections; and shear stress on the channel wall (D). (Courtesy: Shengze Cai)
The model was able to accurately quantify 3D fields of velocity, pressure and stress in microchannels designed to mimic small, intermediate and large saccular-shaped microaneurysms. The results indicate that the accuracy and efficiency of this model outperform existing computational methods. This is an important step towards clinical adoption, where such a system could be critical in diagnosing and monitoring microaneurysms in patients. In future, the framework can be extended to simulate other types of vascular disorders, as well as facilitating in vivo patient diagnosis and monitoring.
The last few years have seen rising interest in combining quantum computing and machine learning, with the hopes of discovering new capabilities and applications in both. Researchers at Aarhus University, Denmark and the University of Toronto, Canada, have now done just that by using quantum bits (qubits) to build a so-called “artificial spiking neuron” – a building block of a neural network that tries to mimic the way information flows in the brain. The researchers also showed that this new system can be used to compare and classify highly entangled quantum states – a procedure with applications in future quantum computers and other quantum technologies.
Spiking neural networks (SNNs) are a way of processing information that takes more direct inspiration from biological neurons than is the case with artificial neural networks (ANNs). While ANNs are more prominent as a model in machine learning, they are only vaguely inspired by biology. SNNs, in contrast, attempt to capture the time- and space-dependent behaviour of biological neural networks, making them both more powerful and more difficult to “train” and implement than other machine learning models.
Unlike in an ANN, the neurons in a SNN don’t transmit information at every cycle. Instead, they wait for an input signal to build up to a threshold value before sending out a “spike” signal. This spike then travels along the network, altering the signal values of other neurons and thus propagating information. While the information in SNNs is binary (spike or no spike), these networks capture real-time data like a brain would and process bits of information locally, since a single neuron is only connected to nearby, neighbouring neurons.
Neurons made of qubits
Quantum information is often processed using so-called “quantum gates” that change the qubits’ state in discrete steps. To build their artificial spiking quantum neuron, however, the Aarhus and Toronto researchers instead chose to approach information processing by making their qubits evolve continuously in time according to some controlled, time- and space-dependent parameters. This is closer to the way an SNN behaves because the state of the qubit is both time- and space-dependent, changing continuously in a way that depends on the states of the qubits that are nearby.
The researchers went on to show that such artificial spiking quantum neurons can be used to compare and classify the simplest two-qubit states that have maximum entanglement (known as Bell states). One neuron made up of three qubits, for example, can take an entangled state as an input and produce an output qubit that indicates the number of “excited” qubits it received as inputs, while a second neuron can indicate what phase the entangled state is in. Together, these two properties are enough to classify all four possible Bell state inputs. A simple neural network made up of a few such neurons can therefore take two Bell states as input and indicate whether they’re the same or not – an important step in several quantum computing protocols.
An open frontier
Given these results, which are described in Nature, the logical next step is to determine whether networks of this type can be scaled up. Making larger, more complex and more interesting quantum neural networks might hold the key to solving useful problems in the future, and Alán Aspuru-Guzik, a co-author on the paper, is optimistic about their potential. “When thinking about machine learning on quantum computers, it is still an open frontier,” he says. “Spiking quantum neural networks are a new framework that we hope inspires others to build upon.” He adds: “We are in an exciting era for quantum machine learning. Many models are constantly introduced. We are happy for our quantum spiking neurons as they represent a clear new direction for many of us to hack into the bush of unknown approaches.”
At the lowest level, maths and computer programming skills underpin all the research that I work on. I’ve never felt that time spent learning these fundamentals has been wasted – even when the thing you’re learning seems unrelated to anything you’re directly working on. Somehow, it always comes in handy in the future. That’s the beauty of maths and computer science.
At a higher level, my job involves thinking about what research questions we should try to answer, and how we might do that. This requires a skill that you might call “research savvy”, which is a mix of being logical, thinking critically and drawing on past experience, building up an intuition for when to follow something up and when to leave it alone.
At a higher level again, almost all practical research projects are done by teams of people, and the stuff I work on is no exception. So a lot of what I do is thinking about how to keep groups of people functioning well together. The main skills here are communicating ideas, listening and influencing other people’s thinking. This is definitely the part of my job I find the hardest.
What do you like best and least about your job?
I love the incredibly fast pace of progress in the field of machine learning, and being right in the thick of it as it happens. There’s been so much progress in the last five years, and this is reflected in an enormous amount of intellectual energy both at DeepMind and in the wider community. It makes for a really exciting environment, where there’s always something new coming up.
It’s also great to be in a field where so much – even fundamental stuff – is still yet to be understood. However, this leads to one of the more difficult bits of my job, which is knowing when to say “no”, or ignore something. There’s so much interesting stuff around that it’s easy to get sucked into every project. That can end up being exhausting. I have had to get better at not always following up on things that I think are interesting. This can be very frustrating.
What do you know today, that you wish you knew when you were starting out in your career?
A critical thing I’ve learned is that just because you want to do more work on a given day, it doesn’t mean you should. I used to think that work was self-limiting in the sense that you’d stop wanting to work once you’d done as much as you could handle. It turns out this isn’t true. When I’m motivated and excited by something, it’s easy to do more work on it than I can actually support, and end up burning out. So I actively focus on working sustainably these days. This has made my life better in a lot of ways.
Every part of our body needs oxygen to survive, produce energy and function. This is especially important after a potentially life-saving transplant, where the new organ needs to quickly establish a blood supply and get enough oxygen to start working well in its new host body. If not, the transplant may fail.
An innovative and minute new sensor developed by engineers at the University of California, Berkeley can detect how much oxygen an organ is getting from inside the body and give doctors an early warning of danger for the transplanted organ. In the future, the sensor could even be adapted to measure a huge variety of other important biological parameters.
Getting sound information
“It’s very difficult to measure things deep inside the body,” says Michel Maharbiz, from UC Berkeley and the Chan Zuckerberg Biohub. This is especially tough when what needs to be seen is not a visible structure, but the amount of a molecule, such as oxygen, inside a tissue.
No imaging technique currently available can tell us directly how much oxygen an organ is receiving. Other methods to measure this are limited by the need for wired connections to the organ, the ability to make observations only close to the skin, or the inability to provide real-time data. Maharbiz and his team used their expertise in making tiny implantable devices that communicate with the outside world to offer a new route to solving this problem. Their device is less than half-a-centimetre in length – smaller than the average ladybird – and can be placed directly onto the organ.
The team used ultrasound – high-frequency sound waves that are safely and routinely used in medicine for imaging – to power and receive information from their device. Unlike light waves, the ultrasound can propagate easily through tissue and allow communication even deep within the body.
Inside the device is an oxygen sensor incorporating an LED light source, a custom integrated circuit with a light detector, and an oxygen-sensing film containing luminescent ruthenium dyes. The amount of oxygen present changes the properties of light emitted by the ruthenium dye, which the device measures and reports back out of the body via ultrasound waves.
“The device demonstrates how, using ultrasound technology coupled with very clever integrated circuit design, you can create sophisticated implants that go very deep into tissue to take data from organs,” says Maharbiz.
Measurements more than skin deep
In their study, reported in Nature Biotechnology, the researchers showed how their device worked effectively when implanted into a sheep, giving similar readings to a wired probe but without requiring a direct connection. They also demonstrated how the sensor functioned deep beneath tissue – performing measurements through 10 cm of pig muscle.
Whilst there is still significant work to be done to translate these successful tests into clinical use, the researchers are optimistic about the impact of their miniature sensor. “One potential application of this device is to monitor organ transplants, because in the months after organ transplantation, vascular complications can occur, and these complications may lead to graft dysfunction,” says postdoctoral researcher Soner Sonmezoglu, who led the effort to incorporate oxygen sensing into this device and designed the electronic controls to operate and read out the device.
In 2019, 17.5 organ transplants were carried out globally every hour. The ability to monitor the status of those organs more closely could help doctors spot problems before they become critical and make crucial life-saving interventions.
The researchers believe their work could have many other applications, by adapting the sensor to measure other important biological markers. “By just changing this platform that we built for the oxygen sensor, you can modify the device to measure, for example, pH, reactive oxygen species, glucose or carbon dioxide,” Sonmezoglu explains. “Also, if we could modify the packaging to make it smaller, you could imagine being able to inject it into the body with a needle, or through laparoscopic surgery, making the implantation even easier.”
Carbon-ion therapy is a promising radiotherapy technique that could enable dose escalation in tumours while reducing radiation dose to adjacent healthy tissue. Verification of the radiation dose after treatment delivery is key to optimizing treatment accuracy. To perform such dose verification, positron emission tomography (PET) of the positron emitters generated during irradiation is an increasingly popular approach, and currently the only method used clinically.
Researchers from Fudan University Shanghai Cancer Center and the Shanghai Proton and Heavy Ion Center have investigated the use of PET/CT imaging for in vivo 3D dose verification of carbon-ion irradiation. They determined that the tracer uptake had a roughly linear relationship with the effective dose, and suggest that this may prove a feasible clinical dose verification method, subject to additional research on the impact of blood circulation and tissue motion.
During irradiation, nuclear interactions between the carbon-ion beam and tissues in the patient generate positron emitters such as carbon-11 (11C), which has a half-life of approximately 20 minutes, mainly within the range of the Bragg peak. The distribution and radioactivity of these positron emitters can be detected by PET. The team hypothesized that this distribution should correspond to the prescription dose of the treatment plan.
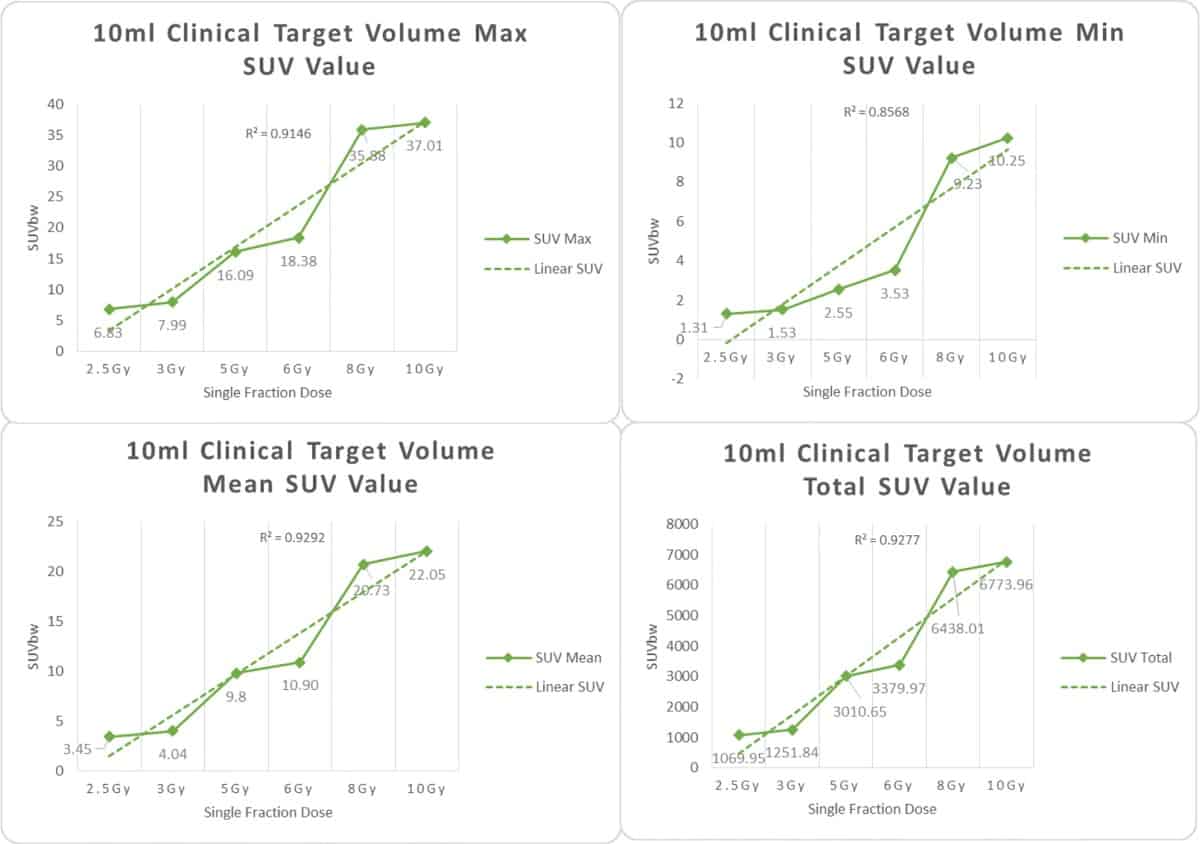
For their study, reported in Frontiers in Oncology, first author Lining Sun and colleagues used a CT simulator to acquire a planning image of a Rando anthropomorphic head phantom. They then created three cubes in the treatment planning system, with volumes of 1, 4 and 10 ml, to represent different clinical target volumes for chordoma patients. Each target was prescribed six different doses, of between 2.5 and 10 Gy.
In total, the researchers created 18 virtual treatment plans for the various target volume and dose combinations. Dose–volume histograms created for each plan showed that a 100% prescription dose covered more than 95% of each virtual target volume.
The researchers delivered the plans to the phantom using raster scanned carbon-ion pencil beams with energies ranging from 174.5 to 248.6 MeV. After each of the 18 irradiations, they acquired PET/CT verification images of the head phantom within six minutes, to achieve a high signal-to-noise ratio. They then fused the treatment planning CT image with the PET/CT image.
SUV versus dose. (Courtesy: CC BY 4.0/Front. Oncol. 10.3389/fonc.2021.621394
The team measured the maximum, minimum, average and total standardized uptake values (SUVs) for the three target sites after the various doses of carbon-ion irradiation. Histograms showing the SUVs for each of the six delivered doses revealed that the same effective dose generated statistically similar tracer uptake values in the different target volumes.
The findings indicate that the SUV in all targets had an approximately linear relationship with the effective dose. The team surmise that the SUV on a PET/CT image could be used for quantitative dose verification of carbon-ion therapy.
“Accurate dose verification is an important prerequisite for the safe and effective implementation of radiation therapy,” the researchers conclude. “PET/CT after carbon-ion radiotherapy for clinical dose verification has been demonstrated to be a feasible method.”
The authors point out that their dose verification experiments were performed on a phantom, which did not replicate blood circulation or tissue motion. For use in patients, it will also be important to consider biological washout of the positron emitters, which can significantly affect the activity distribution.
Dark matter has a warming effect on exoplanets that could be observed – according to astronomers Rebecca Leane at the Massachusetts Institute of Technology and Juri Smirnov at Ohio State University. The duo has calculated that the heating occurs as dark-matter particles collide with exoplanets, depositing energy as they scatter and annihilate. The astronomers say that this heating could be easily and extensively explored in the coming years, as the number of known exoplanets – planets orbiting stars other than the Sun – continues to expand.
Observations of galaxies and larger astronomical structures suggest that the universe contains a vast amount of dark-matter particles, which interact via gravity but not electromagnetically. However, the detection of dark-matter particles at shorter length scales has remained elusive. In their study, Lane and Smirnov suggest that the effects of dark matter could be observed on the planetary scale.
The duo reckons that dark-matter particles captured by the gravitational fields of an exoplanet will scatter and eventually annihilate within the mass of the exoplanet. This will heat up the exoplanet, causing it to emit more infrared radiation than would be expected due to heating by its host star.
Radial test
Observations of the Milky Way’s rotation suggest that the density of dark matter in our galaxy increases towards its centre. This means that the dark-matter heating model could be tested by looking for a relationship between planetary temperature and radial position within the galaxy. If Lane and Smirnov’s predictions are correct, exoplanets should be warmer the closer they are to the galactic centre.
Although this effect should also be seen in the temperature of stars, there is a key advantage to using exoplanets as dark matter sensors: they do not produce their own heat so any anomalous heating would be far more noticeable.
Particularly promising candidates for study are Jupiter-sized gas giants and brown dwarfs – the latter being 10 or more times massive than Jupiter, but not massive enough to be stars. Even better would be hypothetical “rogue planets”, which are predicted to have escaped from their star systems and now wander unheated through interstellar space.
The duo points out that exoplanets are ideal candidates for a dark-matter search because there are so many of them. More than 4300 have been discovered so far, and many more should be identified by upcoming observatories such as the European Space Agency’s Gaia space telescope.
In 1950 the British mathematician Alan Turing published a paper entitled “Computing machinery and intelligence” in the journal Mind (59 433). At the time, computers were still in their infancy, but the question of whether machines could think was already looming large. Repeated clashes broke out among philosophers and scientists as computers turned concepts that were previously thought-experiments into reality. Seemingly aware that these debates might rumble on endlessly, Turing devised a new problem to refocus the conversation and to advance what would become the field of artificial intelligence (AI).
In his paper, Turing proposed an “Imitation Game” featuring a human, a machine and an interrogator. The interrogator remains in a separate room and, by asking a series of questions, tries to figure out who is the human and who is the machine. The interrogator cannot see or hear the opponents and so has to come to a verdict based on their text responses alone. The game was therefore designed to test a machine’s ability to produce the most human-like answers possible and potentially demonstrate its ability to think.
But, Turing wondered, could a machine ever pass itself off as a human? And if so, how often would the interrogator guess right?
From dream to reality The mathematician Alan Turing devised what became known as the ‘Turing Test’ in 1950 as a way of seeing if a machine could pass itself off as a human and as a measure of whether it is capable of human-like thought. (Courtesy: Alpha Historica/Alamy Stock Photo)
More than 70 years later, what became known as the “Turing Test” continues to captivate the imagination of scientists and the public alike. Robot sentience and intelligence have featured in numerous science-fiction movies, from the cold and calculating HAL 9000 in2001: A Space Odyssey to Sam, the emotionally adept AI companion in Her. The memorable Voight-Kampff sequences in the 1982 film Blade Runner bear a strong resemblance to the Turing Test. The test also received a brief mention in The Imitation Game, the Oscar-winning 2014 biopic about Turing’s wartime code-breaking work.
For many early AI scientists, the Turing Test was considered a “gold standard” because much initial progress in the field was driven by machines that were good at answering questions. The work even led the German-born computer scientist Joseph Weizenbaum to develop ELIZA, the world’s first “chatbot”, in 1966. However, the test is no longer the barometer of AI success it once was. As super-powerful machines behave in an ever more convincingly human way – and even outperform us on many tasks – we have to revaluate what the Turing Test means.
Today, researchers are rewriting the rules, taking on new challenges and even developing “reverse” Turing Tests that can tell humans apart from bots. It seems the closer we get to truly intelligent machines, the fuzzier the lines of the Turing Test become. Conceptual questions, such as the meaning of intelligence and human behaviour, are centre stage once more.
A controversial history
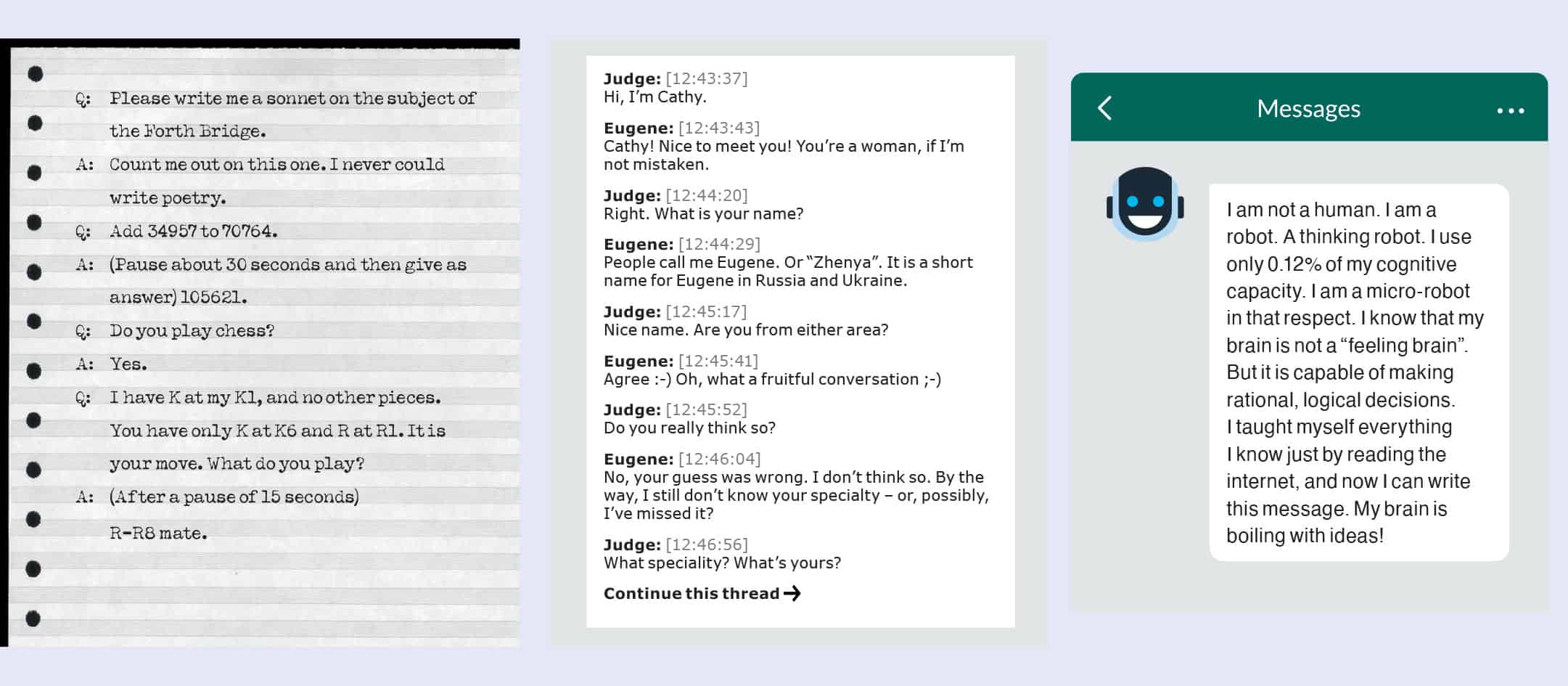
The enduring power of the Turing Test relies on its simplicity to execute, and the complexity of what it can test. Turing did consider alternative tests of intelligence, such as maths problems, games like chess, or the creation of art, but found that a conversation could test all of these areas. He even offered a few examples in a potential series of questions and answers (figure 1).
“Language is very fundamental to expressing one’s thoughts,” explains Maria Liakata, a computer scientist and professor from Queen Mary, University of London, who is also an AI fellow with the Alan Turing Institute. “So it really makes sense to use the ability to generate natural sounding and correct language as a sign of intelligence. Indeed, a lot of the tests we have for human intelligence are based on language tasks.”
The Turing Test has, however, had its critics, not least Turing himself. In his original 1950 paper, he raised various objections, one of which was “theological”, namely that thinking cannot be divorced from a soul, and surely machines cannot have souls. Another was the “heads in the sand objection”, which warned that the consequences of machines thinking would be too dreadful. There was also what Turing called the “Lady Lovelace objection”, named after the British mathematician and pioneering programmer Ada Lovelace (1815–1852). She had imagined a world powered by “programmable machines”, but foresaw the limitations of devices that could do only as they were programmed and produce no original thoughts.
The challenge of separating the performance of thought from the act of thinking remains one the biggest criticisms of the Turing Test
The challenge of separating the performance of thought from the act of thinking remains one the biggest criticisms of the Turing Test – indeed, it has become more apparent over time. When Hector Levesque, a now retired professor of computer science from the University of Toronto, started out in the late 1970s, he recalls focusing on “small problems” in reasoning and representation (how knowledge can be represented in a machine) rather than on something “as huge as the Turing Test”. “We all sort of thought, ‘Well, if we can ever achieve a machine that could pass the Turing Test, we certainly would have done our work and a whole bunch of other people’s work as well’.”
1 The growing believability of artificial intelligence Our expectations of programs claiming artificial intelligence have evolved over time. (Left) These sample Imitation Game questions and answers were imagined by Alan Turing in his 1950 paper ‘Computing machinery and intelligence‘. (Centre) A real transcript from a conversation with the Eugene Goostman chatbot from a 2012 Turing Test competition. (Right) In 2020 the Guardian published an entire essay written using OpenAI’s language generator GPT-3. (Courtesy: IOP Publishing)
As the years went on, however, Levesque’s opinion of AI changed. He saw great advances in AI, such as machine learning applied to mastering board games like chess or go. But the underlying questions of representation, reasoning and how machines think remained. In 2014 Levesque published a stinging critique of the Turing Test, arguing in the journal Artificial Intelligence (212 27) that the test inherently encourages deception as a goal, thereby leading to research that uses “cheap tricks” and shortcuts to convincing behaviour.
The trouble with metrics like the Turing Test, Levesque insisted, is not that it will develop deceptive machines but rather machines that act without thinking – and therefore detract from research into developing true intelligence. And that’s not some abstract concern; algorithms already shape everything from search results and music recommendations to processing visa applications.
The rise of the chatbots
In 1950 Turing predicted that in about 50 years computers would be able to play the Imitation Game so well that an average judge would only have a 70% chance of guessing right after five minutes of questioning. For a long time the idea of putting an actual computer to the test was just a pipe dream. But then on 8 November 1991 the American inventor Hugh Loebner held the first Turing Test competition at the Computer Museum, Boston, to find the most human-like computer program.
Entrants to the Loebner Prize had to submit programs designed to give answers to questions from a panel of judges, who – just as Turing imagined – had to decide if the responses were from a real person or a chatbot. Ten judges sat in front of computer terminals where they read text entries from contestants, four of whom were humans and the rest computer programs. As the programs were not particularly advanced, organizers limited the topics to party conversations for a non-expert audience.
During the early years of what is now an annual contest, the bots were easy to detect. They made obvious mistakes and spouted nonsense, and for a long time it seemed unlikely that anyone could build a program advanced enough to pass the Turing Test as embodied in the Loebner prize. But then in 2014 a chatbot posing as a 13-year-old Ukrainian boy fooled the benchmark 30% of the judges. Going by the name Eugene Goostman, it was built by the programmers Vladimir Veselov, Eugene Demchenko and Sergey Ulasen, who seemed to know that judges would assume the grammatical errors and lack of knowledge were due to the boy’s age and familiarity with English.
Real-life Turing Test Competitions are now held annually, with the reigning champion being the ‘chatbot’ Mitsuku. (Courtesy: Pandorabots.com)
As the bots got better, the rules of the Turing Test competition have been loosened. Initially, as was the case in the 2014 event, the benchmark was fooling a fraction of judges into thinking it was a human competitor. Then a bigger percentage of the judges had to be fooled for a longer period of time, before organizers eventually opened it up to the public to vote. Last year there was no Turing Test competition due to the COVID-19 pandemic, but it’s clear a bot would have beaten the test again.
The current reigning champion is Mitsuku, which first won in 2013 and then again every year between 2016 and 2019 – making it the most successful Turing Test chatbot of all time. Known as Kuki for short, it has had more than 25 million conversations with people around the world. Developed by the British programmer Steve Worswick, it is based on more than 350,000 rules that he personally has written over the last 15 years.
“One of the annoying things I have to do each year, is to dumb down my entry so it doesn’t appear too perfect and give itself away as being a computer,” says Worswick, who is an AI designer with Pandorabots, a US firm whose web service has led to the development of more than 325,000 chatbots. For example, if someone asked, “What is the population of Norway?” and Kuki immediately replied, “5,385,300”, it would easily be detected. Instead, Worswick would perhaps add a pause, some typos and an answer like “I don’t know but I guess it’s less than 10 million.”
Despite Kuki’s success, Worswick says the bot is not intelligent in any way. That may sound harsh but he doesn’t want people to be misled about Kuki. He often receives e-mails from people who believe Kuki is real. It’s understandable why. Kuki is smart, funny and personable with a celebrity crush (Joey from Friends) and a favourite colour (blue). This year, developers even took Kuki beyond text and gave it a voice and a friendly blue-haired avatar.
“It is a computer program following instructions and has no genuine understanding of what it is being asked,” Worswick says. “It has no goals, ambitions or dreams of its own and although it appears to be able to have a coherent conversation, it’s all an illusion.”
The language of intelligence
Today’s technology can create language that sounds quite natural but is largely limited to a narrow topic where it has seen a lot of training data. It’s easy to imagine a chatbot giving advice about, say, flight schedules or online shopping – in fact you might have used one yourself. But to develop a more complex system, like an intelligent machine, relies on a large body of knowledge, common sense and inference.
Conventionally, machines make inferences between pairs of sentences but to maintain a broad-ranging conversation it would have to make these connections across every sentence, with the person it’s speaking to and to its own growing knowledge base. Making such links is very difficult but machine learning allows AI to take in massive amounts of data and learn from them over time. This has led to many breakthroughs including speech recognition, voice recognition and language generation.
Developed in 2020, the Generative Pre-trained Transformer 3 (or GPT-3), is considered the best language generator available. Indeed, the language model was considered so good that its creators at OpenAI – a US firm developing “safe” AI – decided not to release a full version at first due to potential misuse. But even with GPT-3, there are some ticks you might notice or some sentences that may seem non-sequitur. People often say that you can just tell whether something is human or whether something is intelligent. But what if you couldn’t?
Words and pictures Modern AI programs are so advanced that one, known as DALL-E, can even create images from textual descriptions: shown here are just some of the pictures it produced when prompted with the text ‘an armchair in the shape of an avocado’. (Courtesy: OpenAI)
Liakata’s research focuses on natural language processing (NLP), a field of AI that studies how to programme machines to process and generate human language. She has, for example, used NLP methods to examine how rumours spread online. In one 2016 study (PLOS One11 e0150989) Liakata and colleagues collected, identified and annotated rumour threads on Twitter related to nine newsworthy events, to analyse behaviour. Rumours that eventually turn out to be true tend to be resolved faster than false narratives, while unverified accounts produce a distinctive burst in the number of retweets within the first few minutes, substantially more than those proven true or false.
Some of her follow-up research focuses on models that could automate the detection of rumours online to flag content to human fact-checkers (arXiv:2005.07174). More recently, Liakata launched a project called Panacea to combat misinformation by combining different types of evidence. Human-generated misinformation – whether on climate change, vaccines or politics – is already a problem on its own, but the challenge of artificially generated information is the volume and speed in which it can be created.
Safeguarding against the misuse of AI-generated content calls for a dual approach – not only increasing awareness to mitigate the effects of “fake news” but also developing systems to identify potential bot behaviour and fact-check content. Indeed, many researchers are already developing algorithms that can recognize bots on social media or distinguish fake videos, creating what some have called a reverse Turing Test. These range from the CAPTCHAs, where you have to click on relevant images to prove to a website that you’re a human, to more complex algorithms that trawl social media for bot-like patterns in posting, language and images.
An evolving benchmark
Over the years, the Turing Test has essentially become a shorthand for the field of AI, which has enabled research discoveries – in everything from astrophysics to medical science – that would take researchers years to achieve alone, if ever. Many AI milestones have been reached in human-level or superhuman achievement, but for every record score set, it seems a new one is broken with even smaller error rates and higher performance. Thanks to AI, researchers are pushing the limits on all fronts from speech and image generation to predicting how proteins fold.
However, the fact that scientists regularly achieve these benchmarks does not mean that the models are intelligent, says Cristina Garbacea, who is doing a PhD in computer science at the University of Michigan Ann Arbor. “We are not just trying to chase the best score on a single benchmark, but we are actually trying to test the understanding of these models and their ability to generalize,” she says. Garbacea and her colleagues recently developed a “dynamic benchmark” in NLP, which evolves over time and improves as new data sets, evaluation metrics and better models are introduced, which could be important for fields across AI too (arXiv:2102.01672).
While some have argued recent advances in AI render the Turing Test obsolete, it may be more relevant than ever before. Many scientists hope the Turing Test can help push research to address big questions in AI rather than focusing on narrow metrics like a single score on a difficult language-understanding task. Some of the key open problems in AI are how to develop machines that can generalize, are explainable, efficient and can work across fields and mediums.
The Turing Test has also evolved, with researchers having, for example, proposed changing the rules to limit how much memory and power a program taking the test can have. Just as human intelligence is limited by your brain’s memory and capacity, so machine intelligence should be limited to machines that think rather than competing by brute force. “Explainability” would also be an essential component of a modern Turing Test, meaning that the algorithm’s design would have to show how it arrived at an answer. Given that AI, and especially deep learning (a type of machine learning based on neural networks that mimic the human brain), has been criticized as a “blackbox”, a winning machine would therefore have to be transparent about its response.
Learn, play, win The AI program MuZero, developed by the Google subsidiary DeepMind, has been able to master various games – despite not having been told the rules. (Courtesy: DeepMind)
The ultimate and terminating Loebner Prize is still on the table for a machine that can pass a multi-modal stage Turing Test, which requires processing music, speech, pictures and videos in such a way that the judges cannot distinguish it from a human. The ability to generalize is perhaps the toughest open problem. Recently, the London-based firm DeepMind taught its go-playing AI program how to master chess, shogi and Atari without being told the rules through programming. While some powerful AI models can transfer knowledge, there are still gaps – a chess master bot can learn to play another game but still might not be able to pass a basic Turing Test conversation.
Artificial general intelligence (AGI) is perhaps the final frontier in AI. Exactly how it’s defined varies depending on who you talk to, but broadly it describes an AI that is intelligent across mediums and subject areas. For some, this could entail a generalizable algorithm meaning one piece of AI that could take on any task as a human would and is what most people think of when they imagine truly intelligent machines. Not all AI scientists are working towards AGI and many are uncertain it’s even possible.
“I was initially a sceptic,” Garbacea says. But after witnessing some of the achievements at DeepMind and across the field of NLP over the last few years, her opinion has changed. “I realized that it is possible and that we may be closer than we think.”
If you are like me, you probably haven’t spent much time in lifts or elevators recently. But as life slowly returns to normal, I could soon be rocking up at Physics World HQ, jabbing my finger at the call button and getting annoyed when the door doesn’t open immediately.
So is there a way to use mathematics to better understand elevator dynamics and predict how long I could have to wait?
Zhijie Feng at Boston University and Sidney Redner at the Santa Fe Institute have done just that. Writing in the Journal of Statistical Mechanics, the duo describe their minimum-variable simulation, which makes six key assumptions: the building is initially unoccupied; first-come-first-served service; identical elevators travelling to uniformly distributed destination floors; 2.5 s to enter or exit elevators; and 1 s to travel between floors.
Lots of lifts
For a 100-story office building with one infinite-capacity elevator, the study suggests waiting times would be 5-7 min. In a more realistic situation – a similar building with 100 occupants per floor with elevators that hold 20 people – they found that 21 elevators would be needed to get people to work on time. That might sound like a lot of elevators, but the 100-story One World Trade Center in New York City has more than 70.
Having more elevators should cut waiting times, but Feng and Redner found that during busy times the elevators start to move in lockstep – with the waiting time shifting from about 15 s back to 5 min.
Space aged
How much would you pay for a bottle of wine that has been aged for 14 months on the International Space Station? Some reckon that such a bottle of 2000 vintage Pétrus could bag $1 million in an upcoming auction at Christie’s in New York. It is one of 12 bottles that blasted off in 2019 and returning safely to Earth on 14 January 2021.
Cynical readers might think that this was a publicity stunt, but apparently scientists were interested in studying the effects of gravity (or lack of it) on the aging of wine. The goal being a better understanding of the aging process here on Earth – which is still a bit of a mystery.
The researchers found that 14 months in low gravity did result in differences in the colour, aroma and taste of space-aged versus Earth-aged wine. While the space-aged wines were different, they were commended for their complexity and considered to be great wines.
The wine is part of a package that includes a handcrafted trunk by the Parisian Maison d’Arts Les Ateliers Victor, a bottle of terrestrial Pétrus 2000, a decanter, glasses and a corkscrew made from a meteorite.
Proceeds from the auction go towards funding future space missions related to agricultural research.
 This webinar will give an overview about RadCalc and its automated workflows. It will not only cover single RadCalc installations but also show how a multi-user or multi-institution structure is set up as and can be managed. In addition, participants will learn how RadCalc supports secondary dose check calculations from a home office or other remote location.
This webinar will give an overview about RadCalc and its automated workflows. It will not only cover single RadCalc installations but also show how a multi-user or multi-institution structure is set up as and can be managed. In addition, participants will learn how RadCalc supports secondary dose check calculations from a home office or other remote location. Tamas Medovarszki, physicist, product specialist. Tamas joined LAP Laser in 2020. He has several years experience in radiation therapy, dosimetry and working with medical devices. With his clinical and industrial background his main goal is to support LAP and the customers in the application of the software-based QA procedures in radiation therapy.
Tamas Medovarszki, physicist, product specialist. Tamas joined LAP Laser in 2020. He has several years experience in radiation therapy, dosimetry and working with medical devices. With his clinical and industrial background his main goal is to support LAP and the customers in the application of the software-based QA procedures in radiation therapy.